{ }I言語の学習 1.リレーショナルデータベースとSQLとI言語
}I言語の学習 1.リレーショナルデータベースとSQLとI言語
1.1 リレーショナルデータベースとは。
1.1.1 データベースはデータを効率良く記憶し、効率良く検索出来るようした物です。
1.1.2 リレーショナルデータベースは今までのデータベースと異なり、データを一番簡単な構造の2次元の表(テーブル)で持つのが特長です。
1.2 SQLとは。
1.2.1 SQLはリレーショナルデータベースを定義し操作する為の言語です。JIS規格にもなっている国際規格の言語です。
1.2.2 データ構造が簡単なので、SQLも簡単で命令数も少なく、初心者にも容易に習得出来ますが、結構複雑な要求にも簡単に対応出来る優れ物です。
1.3 I言語とは。
1.3.1 I言語はプログラミング言語の1つです。SQLはデータを定義と操作する機能しか無いので、実際にプログラムを完成させるにはプログラミング言語も必要です。
1.3.2 今までのプログラミング言語はかなり難しく、10人が勉強を始めても10人全員が習得出来るような簡単な物では有りません。なので、難しくて専門家しか出来ない事、出来てもプログラミングをするのに時間が掛かってしまう事の二重苦で、一般の企業では基幹業務のシステム化で手一杯で、個々の担当者の仕事のシステム化までは手が回らず、個々の担当者は自分の頭の中で情報処理をして仕事をこなしている状況です。今後益々少子化が進み、働き手が減ってしまう状況に有り、個々の担当者の仕事の生産性を劇的に改善しない限り、この難局は乗り切れません。その為にはプログラミング言語も簡単にし、誰でも簡単に早くプログラミングを出来るようにし、個々の仕事の改善を全員の力で行うしか解決出来ません。
1.3.3 I言語のIはInstantの頭文字で、プログラミングがすぐに出来る意味が込められています、つまり、誰でも簡単に早く出来る事を狙って作ったプログラミング言語です。難しい事、時間の掛かる事はコンピュータに任せる事で解決できると考え、長い期間をかけて開発して来た物で、次の事をして実現しています。
1.3.3.1 データの定義や操作の部分はSQLを使う事で、誰でも簡単に早くプログラミングが出来るようにしました。
1.3.3.2 仕事で得たノウハウを、日々言語に組み込む事を繰り返し、誰でも簡単に早くプログラミングが出来るようにしました。
1.3.3.3 初心者が理解しにくいと思われる難しい技術を、可能な限り使わない事を基本にし、「誰でも」が確実に実現出来るようにしました。
1.3.3.4 SQLはそのまま使っても十分簡単ですが、更に簡単に早く出来るように、SQL関連の命令や変数も沢山用意しました。
1.3.3.5 インストールもメニューも開発支援も運用支援も全てI言語で作り、言語の機能の充実を計ると共に、この部分に問題や改善の必要が出た場合でも、誰でも自力で解決出来るようにしました。
1.3.3.6 I言語自身に問題が出ても、可能な限り自力で解決出来るように、I言語のソースプログラムを公開しました。
1.3.3.7 I言語は、簡単にする為にI言語側で殆どの機能を用意しているので、何でも自由に出来る物では無いで、その点の考慮が必要ですが、豊富な機能を用意しているので、広範囲に適用が可能です。
1.4 今までのプログラミング言語とI言語に対する私見。
1.4.1 初心者が理解しにくい物の1つに関数が有ります。それとは別に関数にはプログラムを解読しにくくしてしまう重大な欠点が有ります、関数は引数を使って変数に値を渡しますが、関数の中では別の変数名が使われるのが一般的ですので、変数名の読み替えが必要で、解読に苦労します。このように初心者が理解出来たとしても重大な欠点が有るので、I言語には関数が有りません。かと言って、関数が無いと、同じプログラムが必要な場合は全てのプログラムに同じプログラムを書く必要が有り、これも問題ですので、I言語では単にコーピーする機能を用意しています。変数名の読み替えは無く、関数の欠点を無くし、長所のみを活かす工夫をしています。
1.4.2 プログラム作りは作って終わりでは無く、作った後に問題点が発見されたり、機能修正や追加が必要に成ったりで、プログラムは常に変更し成長させる必要が有り、プログラムを誰でも簡単に解読出来る事も重要です。その点で関数は問題がありますが、更に複雑にしているのが、構造化プログラミングです。これにより、不必要にプログラムが細分化され、益々解読が困難になってしまいました。
1.4.3 更なる問題は構造化プログラミングで言われたgoto命令悪者説です。つまり、goto命令がプログラムを複雑にし解読しにくくしていると言う意見です。あくまでも私見ですがgoto命令は被害者で加害者は条件分岐命令です。gotoが悪いと言う事でプログラマーはgoto命令が無ければ良いと勘違いし、ifとelseの混在したステップを何十行も書いてしまい、殆ど解読不能なプログラムが多くなり、苦労させられました。論理回路の設計はカルノー図を使って条件分岐の回路を単純にする事をしていますが、プログラミングに関しては条件分岐を単純にすべきと言っている人が殆どいないので、難しいままです。
1.4.4 プログラムを解読しにくくするとどめを刺してしまったのが、オブジェクト指向プログラミングです。関数は変数名の読み替えだけで済みますが、オブジェクト思考の場合はインスタンスの名前からクラスの名前に読み替える余分な作業が増え、特に初めて見る人には非常に解読が困難なプログラムとなってしまっています。
1.4.5 解読が大変なのでプログラムは作った本人が保守を担当し、担当が変わる場合は引き継ぎをする事が行われており、解読しにくい問題が放置されたままに成っています。
1.4.6 I言語の1つ前のIPROGAMの場合ですが、退職時に知らべたところ、1個のプログラムを数人が修正している物が沢山有り、一番多い物は10人を超えており、誰でも解読出来る事が実証されています。I言語はIPROGRAMを更に解読のし易さも考慮し再設計した物です。
1.4.7 I言語には初心者には理解が困難な物は使っていないのでここで列挙しておきます
1.4.7.1 関数★引数や戻り値、ヘッダーファイルの知識も不要です。尚、標準ライブリ関数の知識も不要で、I言語に組み込まれていない標準ライブラリ関数は使えませんが、「誰でも」の方を優先している為です。
1.4.7.2 オブジェクト指向プログラミング★クラス、インスタンス、メソッド、カプセル化、継承、等々沢山の単語が登場しますが、すべて、習得不要と言う事に成ります。
1.4.7.3 予約語★命令の書く部分を明確に分離する書き方とする事で予約語を覚えなくても良いようにしているので、書き方が他のプログラミング言語とは大きく異なります。
1.4.7.4 配列★名前に連番を含める事で配列と同じ事が出来るようにしています。
1.4.7.5 データ型と共用体★I言語内の変数は全て文字型です。
1.4.7.6 構造体と列挙体と三項演算子★無くてもプログラムが作れるので無用としました。
1.4.7.7 ポインタ★変数名を変数名で修飾する事は出来ます。
1.4.7.8 if命令のelse★ifとelseの入れ子構造のプログラムは解読が難しく成るので作れません。
1.4.7.9 forとwhileとdoとswitch命令★初心者の理解しにくい命令は使わないで、関数同様簡単な命令で実現しています。
1.4.7.10 GUI★GUIを使えば、複雑なプログラムを作る事ができますが、誰でも簡単に早くは無理ですので、最低限をI言語側で用意した物以外は使わない事としました、。
1.5 SQLによるシステム開発。
1.5.1 SQLは文法は簡単ですが、事務処理系システム開発に必ず必要な機能も用意されています。
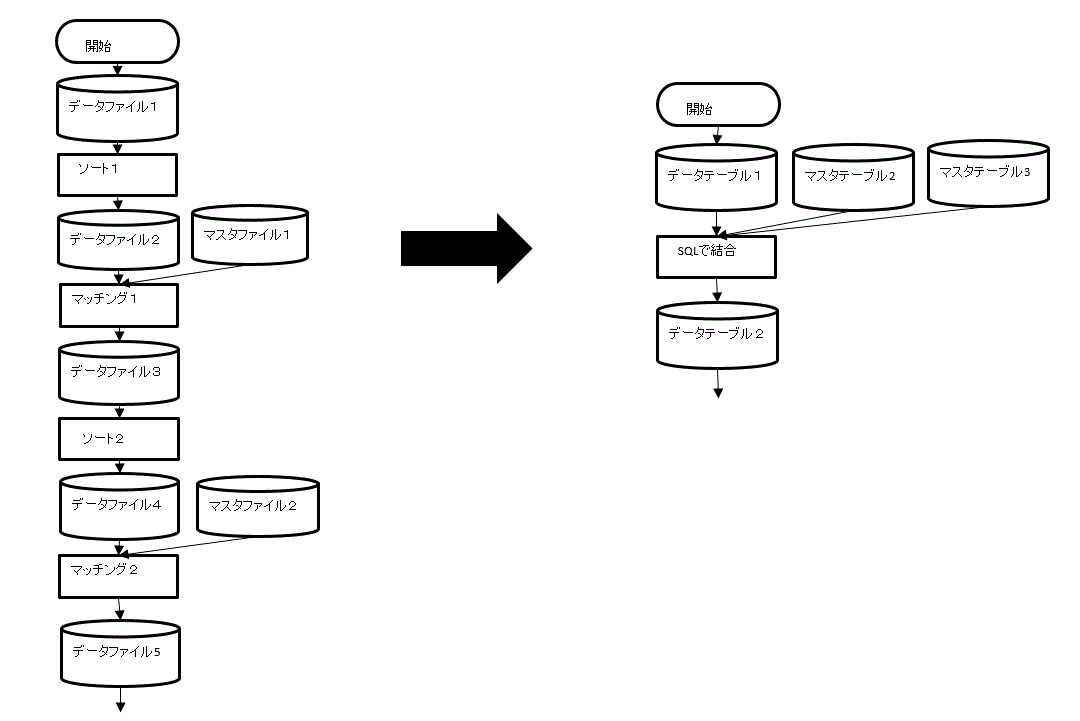
1.5.2 例えば、バッチ系(データをまとめて処理する)では、キーとなる項目単位にマスタファイルを作り、処理はデータファイルをマスタファイルのキー項目順にソート(キー項目順に並び替える)して、データファイルとマスタファイルをマッチング(キー項目の同じ物を突き合わせる)するプログラムを作り、マスタのデータをデータファイルに付加したり計算をしたりする事を繰り返して、生産管理や給与計算と言ったシステムを構築していました。
1.5.2.1 SQLは、ソートもマッチングも不要で、単にSQLでテーブル同士を結合する事で実現が可能に成っています。
☆I言語ではサーバーでI言語をバッチ処理として動かす為のプログラムを持ち、スケジュールに合わせて時間で起動させる事が出来るように成っています。
。
1.5.3 オンラインリアルタイム系(オライン端末で操作する)では条件を入力して条件に合った物を検索表示するようなプログラムが多いですが、この場合もSQLで条件を設定して簡単に検索するプログラムが作れるようになっています。
1.5.3.1 I言語ではクライアントでI言語を画面を使ってメニューから動かす為のプログラムを持ち、オンラインリアルタイム処理に対応出来るように成っています。
1.5.4 このように、データをファイルで持って全てをプログラミング言語で対応するよりも、データをリレーショナルデータベースに持ってSQLを使う事で、システム開発が容易に出来るようになります。
1.6 テーブル構造。
1.6.1 実際のデータは2次元の表で表現出来るような簡単な構造では無いので、2次元の表にする事は、正しい構造にする事では無く、あくまでも矛盾が起きにくい構造にする事ですので、ニーズが変化すれば、おのずとテーブルの構造も変化させる必要があります。
1.6.2 テーブルの縦方法は列(カラム、フィールド)と呼び列名を設定し、それぞれのデータの名前を指定します、住所録であれば、名前、住所、電話番号等が列名と成ります。
1.6.3 テーブルの横方向は行(ロー、レコード)と呼び、1件づつのデータと成ります。
住所録テーブル| 名前 | 住所 | 電話番号 |
|---|
| 田中実 | 東京都... | 03-... |
| 佐藤和子 | 北海道... | 011-... |
1.6.4 テーブルの単位はそのデータを他の行と区別できる列(主キーと呼び、複数列の場合も有ります )とその列が決まれば他の列も決まる物を合わせたものを、一個のテーブルとします。
1.7 テーブルの正規化。
1.7.1 テーブル構造を決めるのに正規化と呼ばれる方法を使いますが、6種類の正規化まで有り、結構難しいですが、正しい構造にする為の物では無いので、取りあえず作って、問題が出たら修正すれば良い程度に考えれば良いです。つまり、実際にプログラムを作って動かしてみないと問題点は見つからないので、設計時点で完璧な構造のテーブルは残念ながら作れません。
1.7.2 第1正規化は導出項目と繰り返し項目を排除する事です。
1.7.2.1 導出項目とは他の列から導き出せる物です、例えば、単価と数量と金額は単価×数量=金額ですので、金額は排除します、これは単価や数量が変更された時点で金額を変更しないと、データが正しくない状態に出来てしまうので、毎回金額を計算して出すようにします。ただし、処理効率を考慮しあえて持つ場合も有ります。
1.7.2.2 繰り返し項目とは同じ内容の情報が複数有る場合は1行内で繰り返すのではなく、複数行に分けて持つ事です。例えば、家族を考えた場合、名前は1人づつ有るので人数分の行を持つ事で対応します。
1.7.3 第2正規化以降は主キーと主キー以外の持ち方です、主キーがどれかとその主キーに従属する列はどれかを探し、1個のテーブルとします。簡単に言うと、データが発生した時点で一緒に発生するデータを集め、主キーを単位に分割してテーブルを持つようにする事です。
1.8 SQL文。
1.8.1 代表的な定義文を7個と、操作文4個です。他にも有りますが、これだけ習得すれば殆どのプログラムが作れます。
1.8.2 データ定義言語(DDL,Data Definition Langage)。
1.8.2.1 テーブルを作成する。
◆CREATE TABLE テーブル名(列名 データ型[NOT NULL][DEFULT 初期値][,...])
([]内は省略可能の意味で...は繰り返し可能の意味です)
(データ型はCHAR(文字数)が半角文字[日本語を含まない]、NCHAR(文字数)が全角文字[日本語を含む]、DECIMAL(有効桁数,小数部桁数)等です)
(「NOT NULL」は値無しのNULLが登録出来ません)
(「DEFAULT 初期値」はその列に何も登録しなくても初期値が入ります、「NOT NULL」を指定した場合何も登録しないとエラーと成るのでDEFAULTを設定します)
1.8.2.2 テーブルを修正する。
◆ALTER TABLE テーブル名 xxxxx
1.8.2.3 テーブルを削除する。
◆DROP TABLE テーブル名
1.8.2.4 インデックスを作成する。
◆CREATE[UNIQUE]INDEX インデックス名 ON テーブル名(列名[,...])
(検索を早くしたい場合に設定します)
(「UNIQUE」は重複を認めないユニーク制約の設定が出来ます)
1.8.2.5 インデックスを削除する。
◆DROP INDEX インデックス名 ON テーブル名
1.8.2.6 アクセス権を作成する。
◆GRANT アクセス権[,...]ON テーブル名 TO ユーザー[,...]
(他のユーザーIDにアクセス権を付与します)
1.8.2.7 アクセス権を削除する。
◆REVOKE アクセス権[,...]ON テーブル名 FROM ユーザー[,...]
(他のユーザーIDのアクセス権を取り消します)
1.8.3 データ操作言語(DML,Data Manipulation Langage)。
1.8.3.1 データを削除する。
◆DELETE FROM テーブル名 [WHERE 条件]
(「WHERE 条件」で条件を設定しないと全行が対象に削除されます)
1.8.3.2 データを作成する。
◆INSERT INTO テーブル名[(列名[,...])]VALUES(内容[,...])[,(内容[,...]),...]
◆INSERT INTO テーブル名[(列名[,...])]SELECT xxxxx
(書き方が2種類有ります、最初は値を指定する場合で、次はSELECTの検索結果で作成します)
(列名を省略出来ますが、テーブルの列数に変更が有るとエラーと成ってしまうので、必ず書く方法を推奨します)
1.8.3.3 データを修正する。
◆UPDATE テーブル名 SET 列名=内容[,...] [WHERE 条件]
◆UPDATE 別名 SET 列名=内容[,...]FROM テーブル名 別名,テーブル名 別名[,...]WHERE 結合条件等(注:RDBMSで文法が異なります)
(書き方が2種類有ります、最初は1個のテーブルの場合で、次は2個以上のテーブルを使う場合です、最初の場合でもサブクエリー[カッコで囲んだSELECT文]を使えば別のテーブルも扱えます)
(「WHERE 条件」で条件を設定しないと全行が対象に変更されます)
1.8.3.4 データを検索する。
◆SELECT [DISTINCT]式[,...][FROM テーブル名[別名][結合 テーブル名[別名]ON 結合条件][...]]][WHERE 条件][GROUP BY 式[,...]][HAVING 条件][ORDER BY 式[DESC][,...]]
(「DISTINCT」を書くと重複行が1行になります)
(「結合」でテーブルを結合し1個のテーブルとみなして扱えます)
(「GROUP BY」を書くと合計、件数、平均、最大、最小等の集計関数が、グループ単位に集計出来ます)
(「HAVING」の条件は集計関数の結果を条件に含めたい場合に使用します)
(「ORDER BY」は表示する順番を指定できます。「DESC」を書くと降順になります)
All Rights Reserved, Copyright (C) 2017-2017 Nobumichi Harasawa.