{ } I言語VER8システム開発の入門編 7/9 (ひらがな項目の追加)
} I言語VER8システム開発の入門編 7/9 (ひらがな項目の追加)
(7)ひらがな項目の追加。
☆せっかくですので一番難しい事をしてみます,市実表は「市」を主キーとしていましたが,
新しく追加するひらがなの「し」を主キーにしてみます。
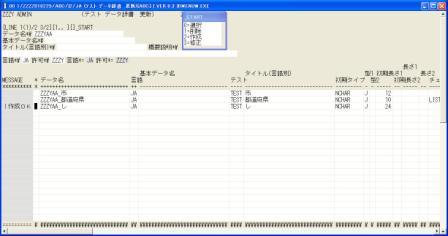
◎(7.1)「システム 開発 メニュー」で'25'を入力し「テスト データ辞書 更新」に行き,
[Enter]で検索します。
'←','↓','↓','2','ZZZYAA_し','JA','','TEST','し','NCHAR','J','',
'24'(初期長さ1,ひらがなの最大文字数不明に付き漢字の2倍としました),'↓',[Enter]で作成します。
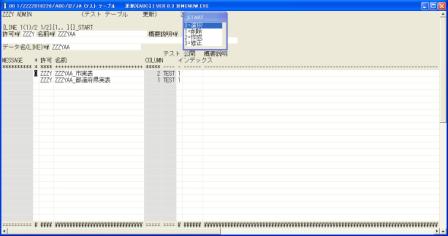
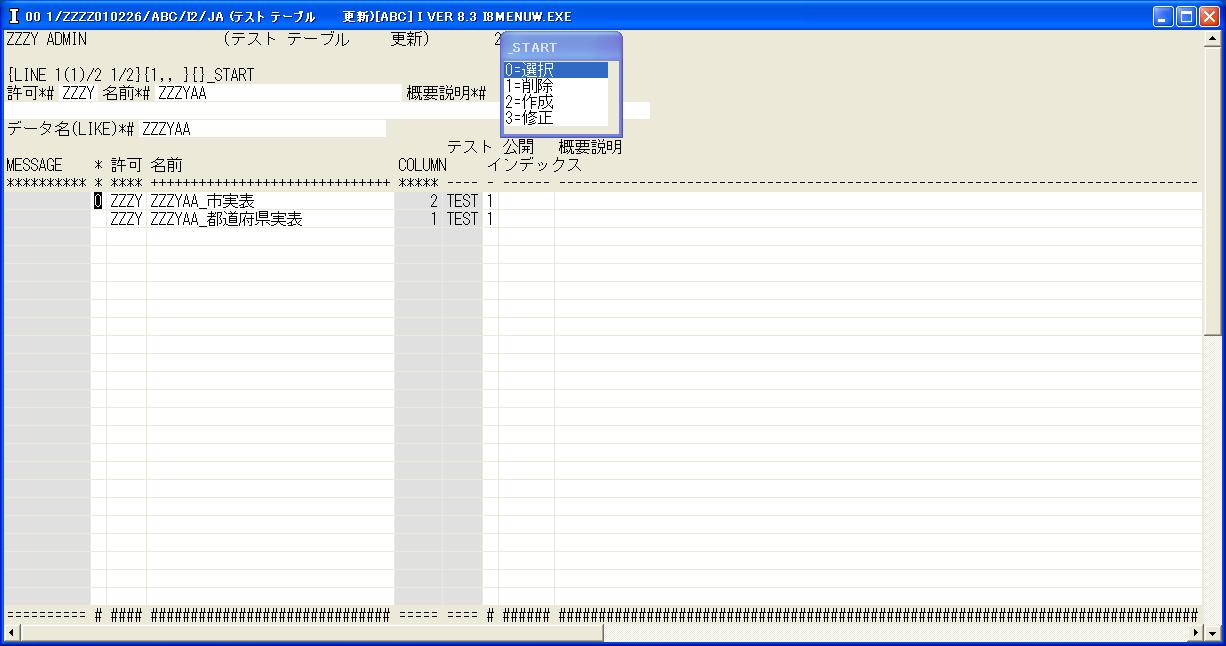
◎(7.2)「システム 開発 メニュー」に戻って'26'を入力し「テスト テーブル 更新」を起動します。
[Enter]で検索後,'←','↓','0'で「ZZZYAA_市実表」を選択します。
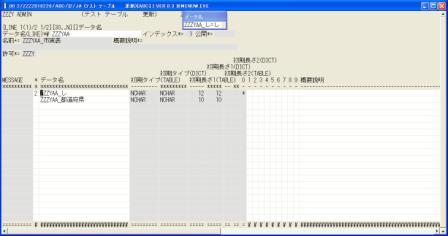
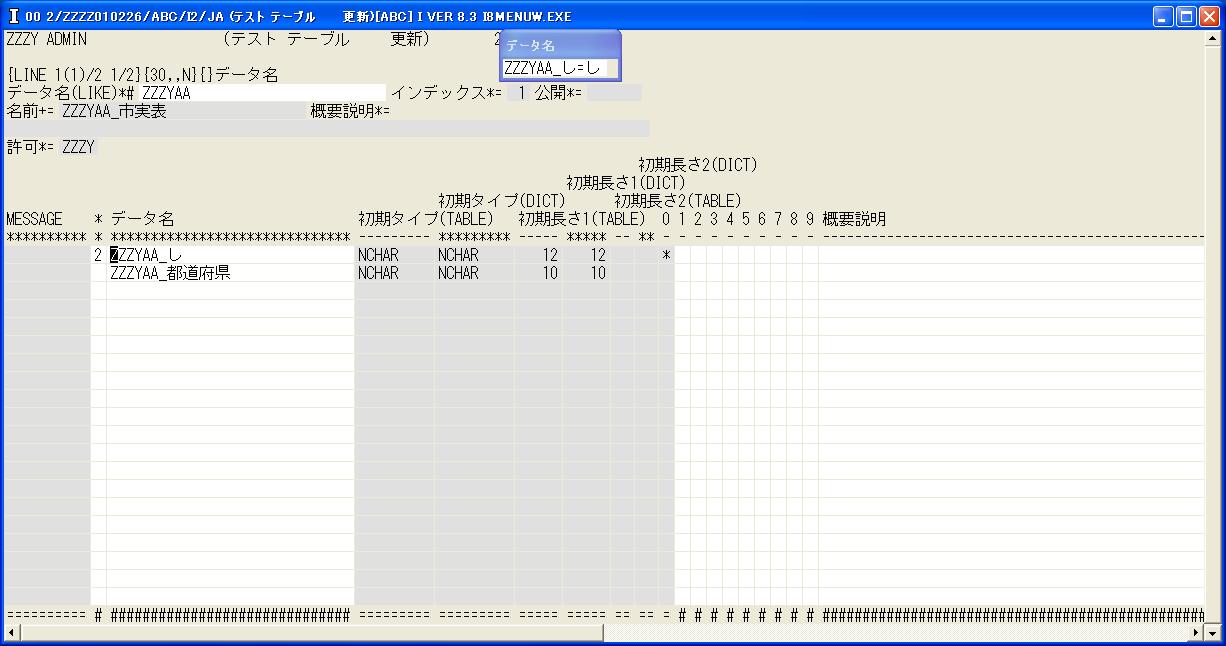
◎(7.3)主キーとするため'←'で先頭の「ZZZYAA_市」の場所で'2','ZZZYAA_し'を選択,'↓'で[Enter]します。
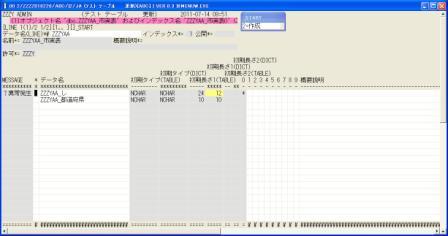
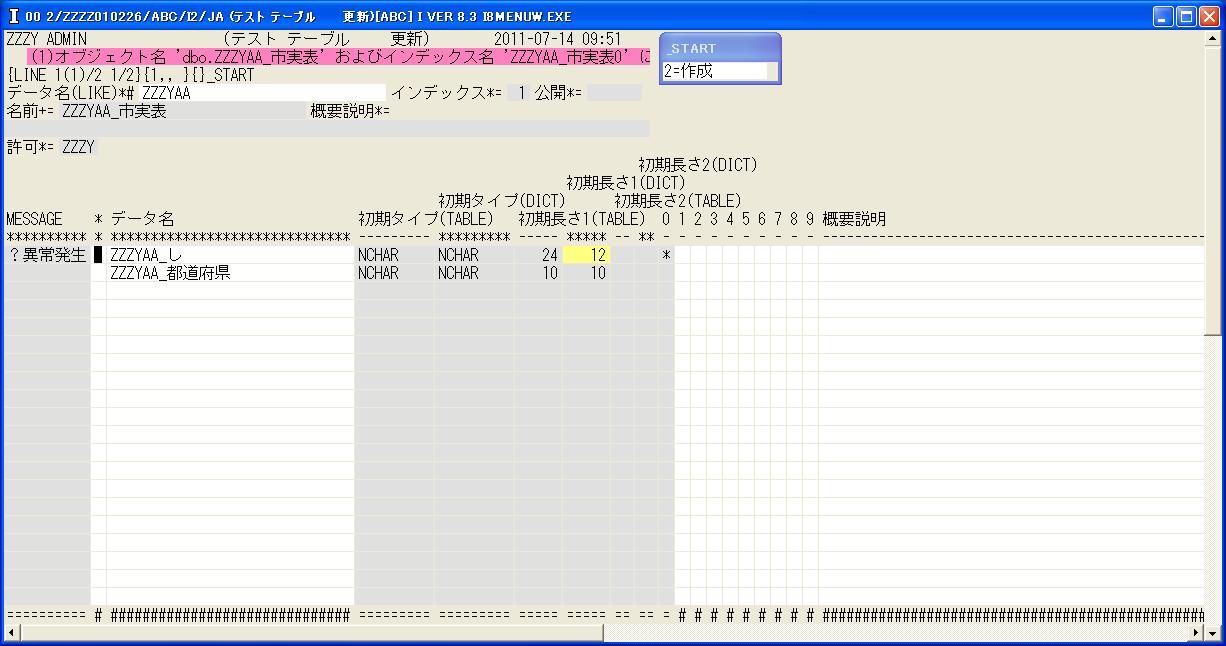
◎(7.4)「(1)オブジェクト名 'dbo.ZZZYAA_市実表' およびインデックス名 'ZZZYAA_市実表0' に」とエラーになります。
これは新たに作成した「ZZZYAA_し」を主キーとしようとしましたが,新項目のため全て空白となっており,
結果同じ文字が重複してあるため,インデックスが作れませんでした。
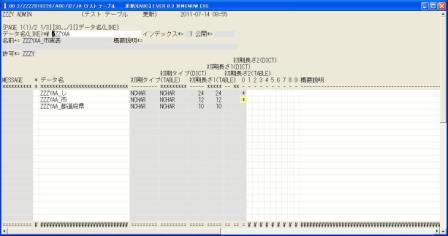
◎(7.5)'←',[Enter]で再表示させると,テーブル上のデータ名としては登録されています,
つまり,インデックスだけが作れない状態です。
そこで,この時点でインデックスが作れるように「ZZZYAA_し」に正しい値を入れる事にします。
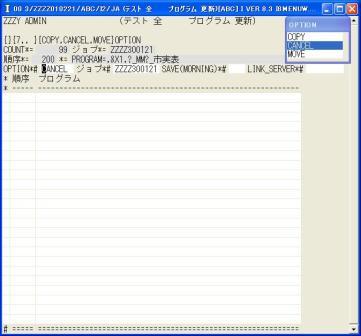
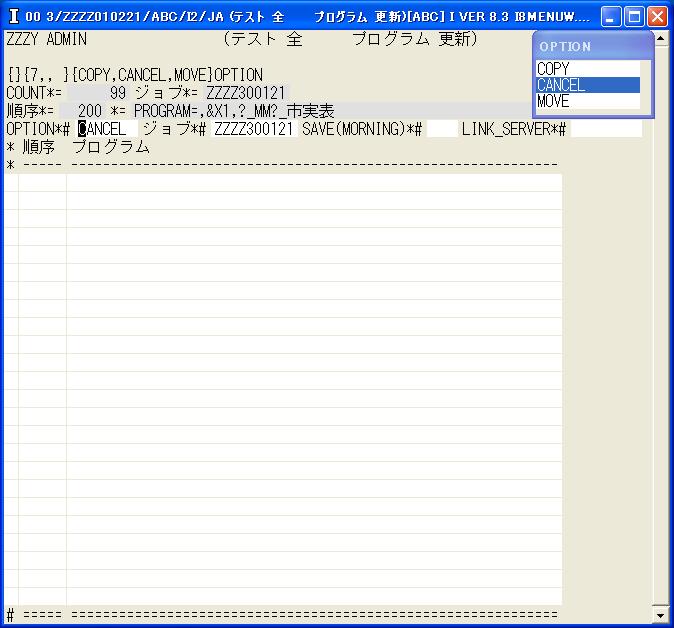
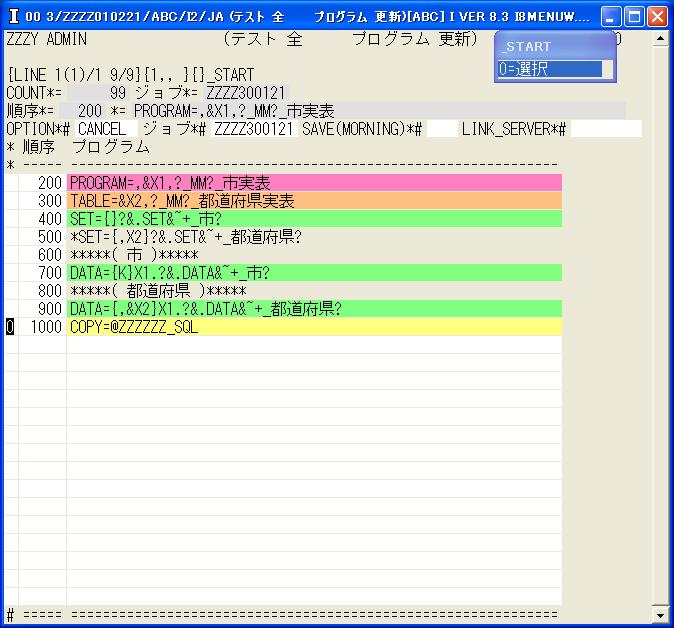
◎(7.6)「システム 開発 メニュー」に戻て'21'を入力し「テスト 全 プログラム 更新」行き。
ZZZZ300121のプログラムを選択します。そこで,先頭の行を'0'で選択します。
上記の画面に変わるので、OPTIONで'CANCEL'を選んで[Enter]で検索します。
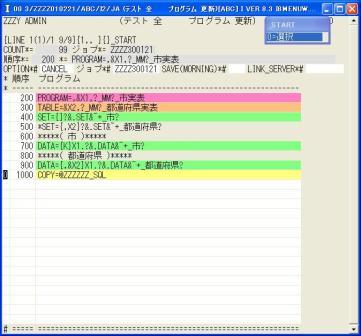
◎(7.7)検索した最後の行を'0'で選択します。
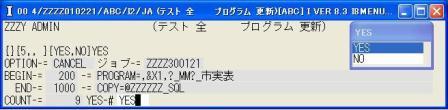
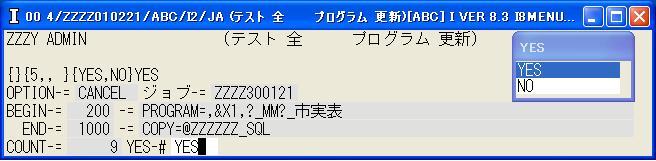
◎(7.8)200から1000までCANCELするか確認の画面が出るので,'YES',[Enter]で実行します。
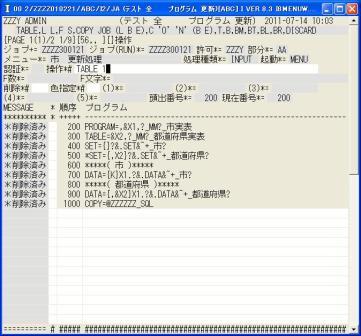
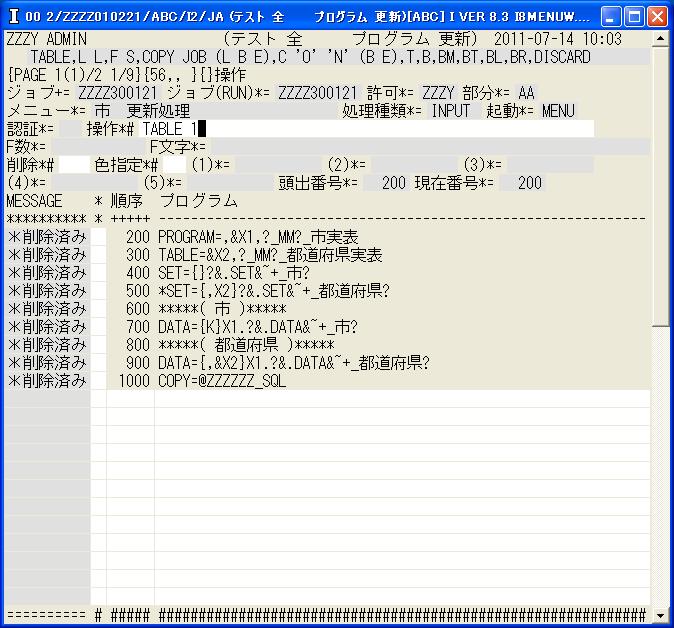
◎(7.9)プログラムの画面に戻り全ての行が削除されているのが分かります。
ここで,再度'TABLE 1'で市実表からプログラムを作ります。
(註:TABLEの次の1はテーブル数で,こうするとテーブル数を入力する
画面を表示しないで先に行きます)
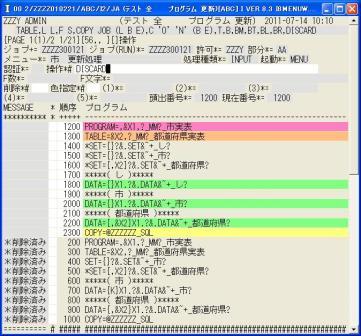
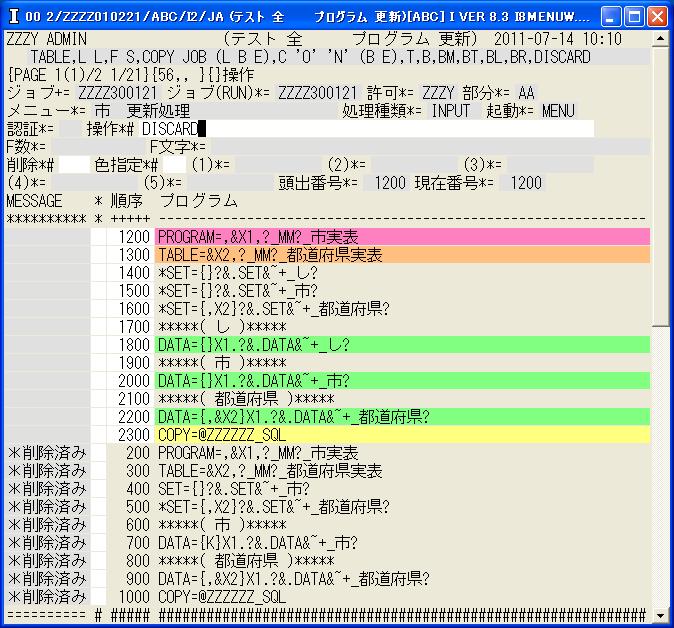
◎(7.10)"ZZZYAA_市実表"を選んで出来たプログラムです。
削除データの順序番号を使っていないので1200から始まっています。
削除データが最後にまとめて見えます。
尚,削除データーを本当に削除したいときは,操作で'DISCARD'とすれば全て消えます。
また,順序の番号をきれいに振りなおしたい場合は,操作で'RENUMBER'とすれば振りなおします。
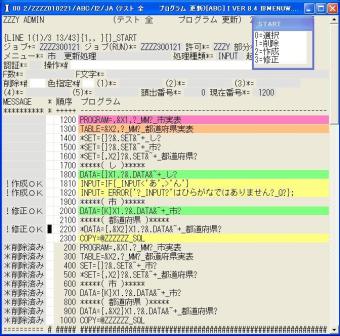
◎(7.11)テーブル作成でエラーとなったため,主キーが存在しないテーブルとなりDATA=の次の{}内に「K」の有る
データが一つも存在しません,これでは,更新キー無ですので更新処理が正しく動きません。
そこで,前回更新キーで有った「ZZZYAA_市」を再度更新キーとするため2000の
「2000 DATA={}X1.?&.DATA&~+_市?」を
「2000 DATA={K}X1.?&.DATA&~+_市?」に変更します。(Kを追加し更新キー化)
さらに、ZZZYAA_都道府県は今回は修正しないので2200の
「2200 DATA={,&X2}X1.?&.DATA&~+_都道府県?」を
「2200 *DATA={,&X2}X1.?&.DATA&~+_都道府県?」に変更します。(先頭に*を追加でコメント化)
これで,プログラム上は「~+_市」が更新キーで,「~+_し」が更新対象となりました。
今回は更に「~+_し」にはひらがな以外を入力した場合はエラーとします。
(VER8.4とVER7.35で、INPUT=命令と_INPUT変数を新設し、入力時点の文字を判定できるようにしました)
1800以下に次のプログラムを作る事で実現できます。
1810 INPUT=IF{_INPUT<'あ',>'ん'}
_INPUTで入力直後の文字を判定し、'あ'より小さいか又は'ん'より大きい時すぐ次の命令を実行し以外の時は「;」(セミコロン)までスキップします。
(IF内の[,]は「又は」(OR)の意味になります、比較の左辺がない場合は1つ前の左辺と同じと見なします、尚、IF{...}IF{...}とした場合は他の言語とは異なり単に「かつ」(AND)の意味になります。)
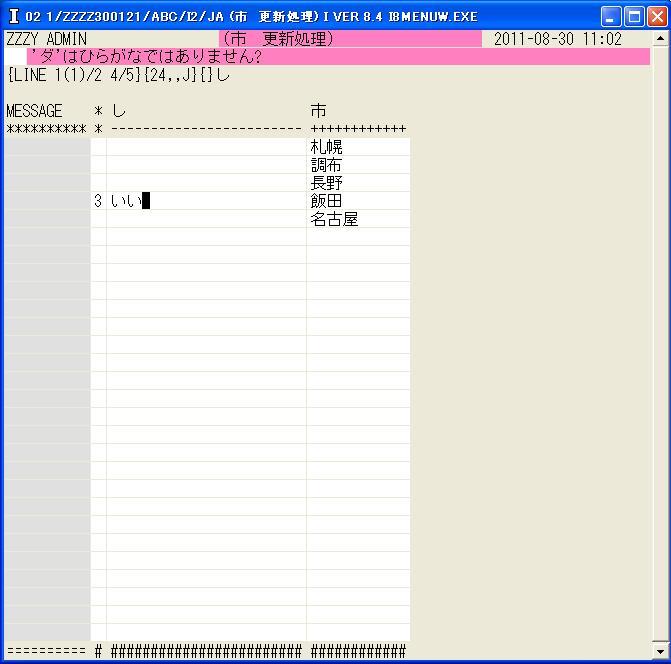
1820 INPUT= ERROR{'?_INPUT?'はひらがなではありません?_Q?};
ERRORでひらがな以外の文字をエラー表示します。
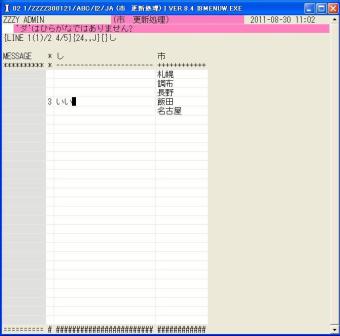
◎(7.12)'3'修正でためしに'いいダ'と入れると、ダは入力されないで2行目にエラーが表示されました。
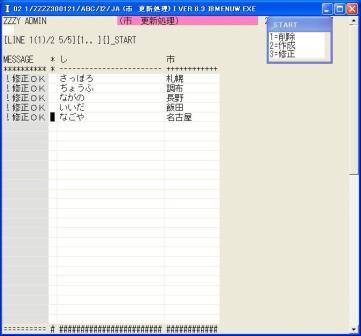
◎(7.13)'3'修正で全てのデータを修正します。
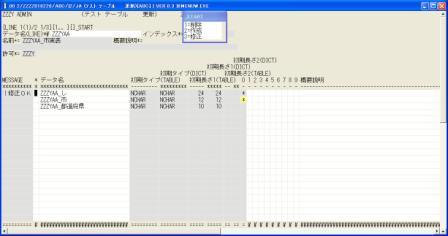
◎(7.14)正しくインデックスを付けるため、「テスト テーブル 更新」に戻って[Enter]で検索、'←','↓’,で'0'で、ZZZYAA_市実表を選択します。
'←','3'(修正),'↓'で最後に行き[Enter]で今度はエラーにならないで修正OKと出ました。
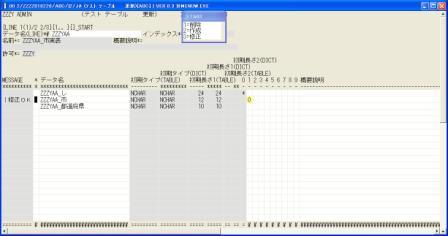
◎(7.15)~+_市も唯一無二ですので、一応重複登録出来ないユニークインデックスを設定します。
インデックスは1から9まで9個を主キーとは別に設定できます、ユニークキーの設定は0から指定します、重複を認めるインデックスは1から指定します。
'↓','3'(修正),[Tab],'0'(1、ユニークインデックスなので0を設定)'↓',[Enter]で修正します。
(インデックスは大量のデータを検索する場合の検索効率を上げるための物ですが、ユニークインデックスでは重複が有るとエラーになります)
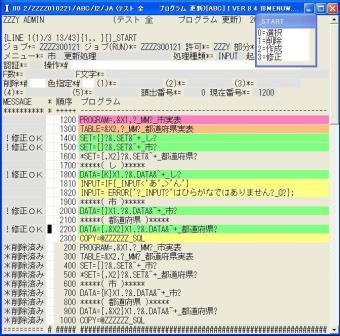
◎(7.16)「テスト 全 プログラム 更新」に戻ってZZZZ300121の「市 更新処理」を本来のプログラムに改造します。
1400と1500の*を取り、1800にKを付け、2000のKを取り、2200の*を取ります。'TEST'で実行します。
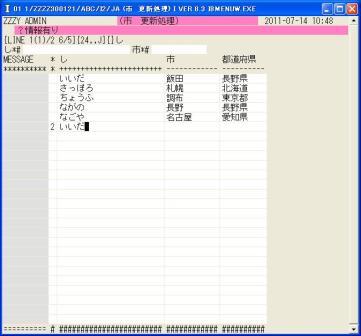
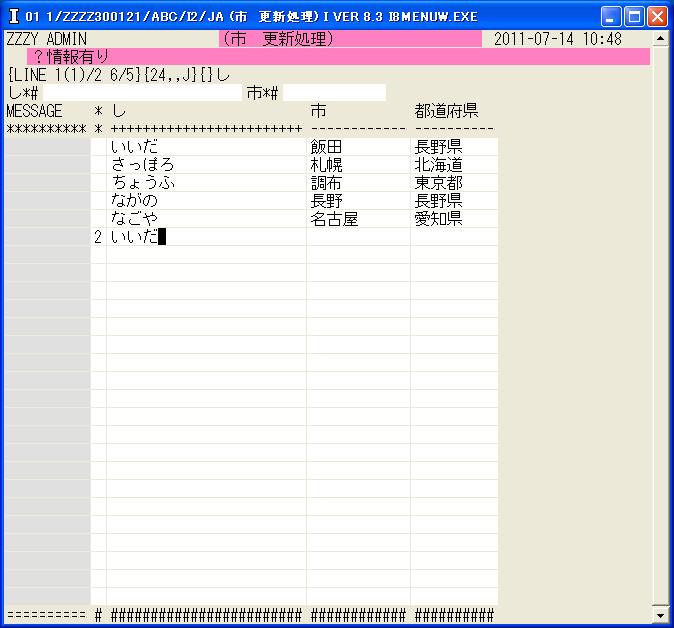
◎(7.17)ここで試しに'2'(作成)で「~+_し」に重複データの「いいだ」と入れてみます、「?情報有り」をI言語が表示して再入力されます。
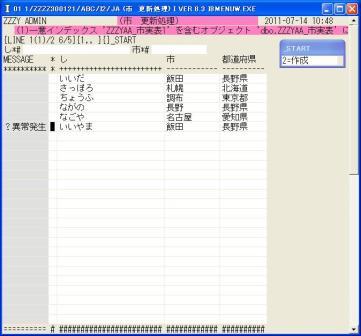
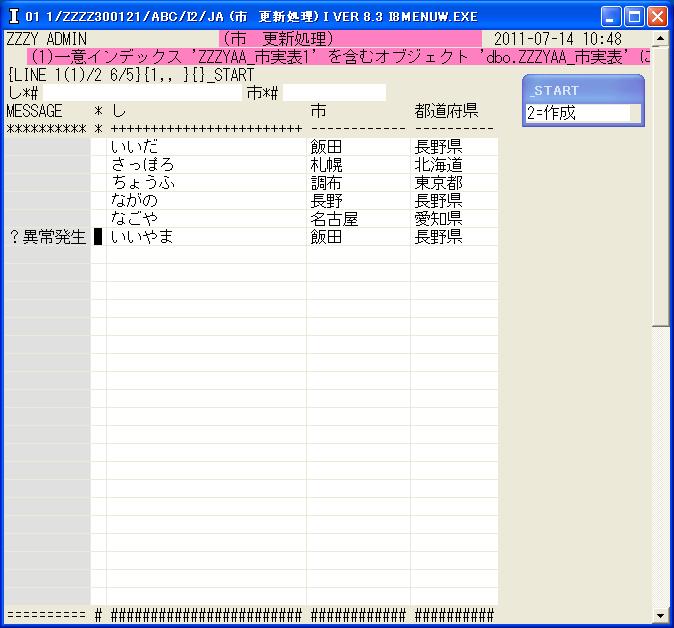
◎(7.18)次に'2'(作成)で「~+_し」は重複なしの「いいやま」、「~+_市」には重複データの「飯田」と入れて作成してみます。
今度はI言語では入力できましたが、作成時点でデータベースが重複エラーを返しました。
コメントが「?異常発生」では、操作している人がびっくりしますので、プログラムで対応します。
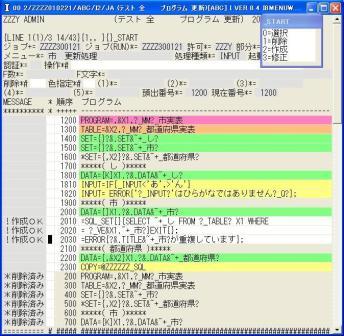
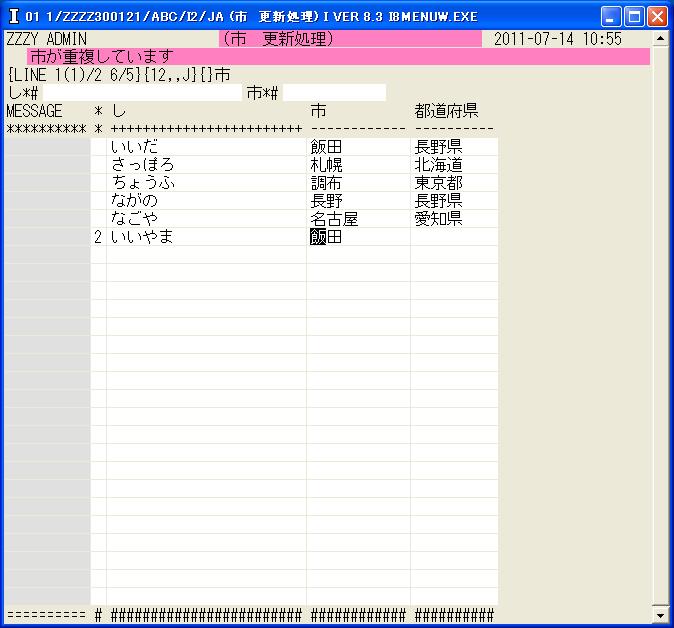
◎(7.19)「テスト 全 プログラム 更新」に戻ってZZZZ300121の「市 更新処理」をに重複チェックを追加しました。
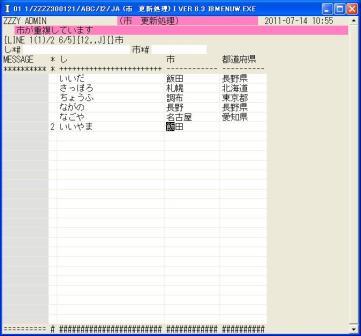
◎(7.20)テスト続行で今度は「飯田」入力時点でエラー表示しました。
プログラムを説明します。
2010 =SQL_SET{}{SELECT ~+_し FROM ?_TABLE? X1 WHERE
SQL_SETはSQLを発行し受信データを1件のみ受取り、受け取った場合は「;」までスキップします。
次の{}は本来は受信データの転送先を指定します、今回はデータがあるか無いかの判定ですので受信データはどこにも転送しません。
「SELECT ~+_し FROM ?_TABLE? X1 WHERE」はSELECTのSQL文の先頭です。
2020 = ?_VE&X1.~+_市?}EXIT{};
「?_VE&X1.~+_市?」は先頭がアンダーバーなのでシステム提供データ名ですが、途中に&がある場合は以降のデータ名を元に比較文字列を組み立てます。
VはValueの意味で値と比較します、EはEqualの意味で一致比較をします、今回は「X1.ZZZYAA_市=N'飯田'」の文字列となります。
通常は「AND Z_CANCEL=' '」が必要ですが、削除データと重複した場合もエラーとなるので今回は指定しません。
EXIT{};で受信データが無い、つまり、重複がない場合は次の入力に行きます。
2030 =ERROR{?&.TITLE&~+_市?が重複しています};
受信データが有った場合はエラーとなります。
?&.TITLE&~+_市?はこのデータ名の言語に合わせたタイトルに変換します。
これで、ひらがな項目の追加は完了です。
次へ(8/9,承認機能の追加)
All Rights Reserved, Copyright (C) 2011-2011 Nobumichi Harasawa.